

I’ve been toying with Perplexica over the last few weeks occasionally, it feels really restrictive.
I’ve had to modify the internal prompts to make it generate better search terms with my SearxNG (And depending on what LLM model you use, you need to fine tune this…) and having to rebuild the container image to do this has just been annoying. Overall, I’ve had experience with self-hosted LLM web searches on Open-webui, but perplexica is a fun project to try out nevertheless.

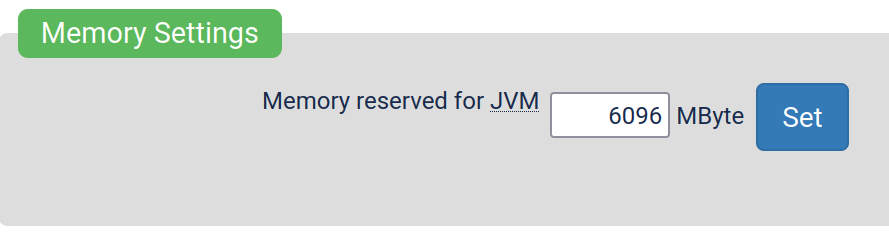


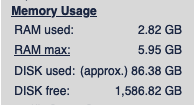
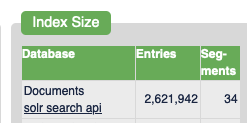

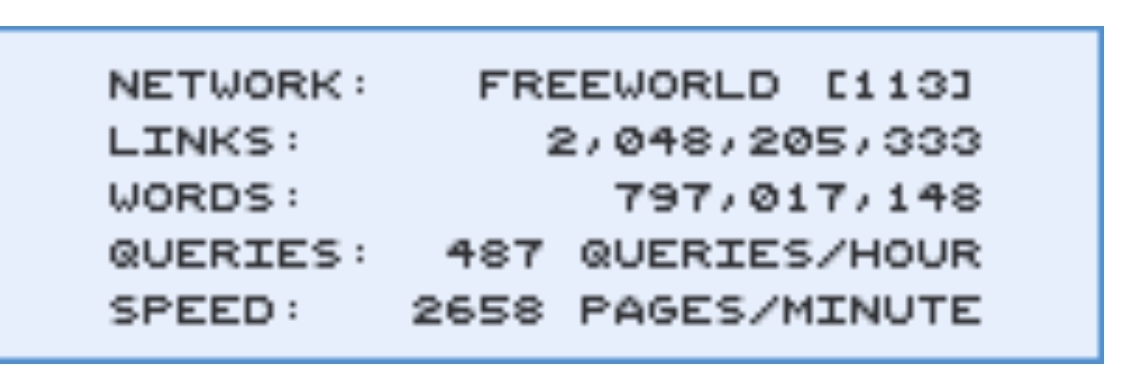
I’m not advocating for breaking any rules, but many people dont know that you can hide your wifi routers SSID. even fewer people know how to track these networks.